
What is Fuzzing?
Fuzzing is the act of generating a large number of inputs that can be either random or mutated from known good inputs. These inputs are then entered into the target application in order to observe crashes or odd functionality. To this end, fuzzing can be used from a defensive side for hardening an application or from an offensive side to find vulnerabilities in a given target. There are also multiple types of fuzzing that a researcher could rely upon. White-box, Grey-box, and Black-box fuzzing are the most commonly used terms to describe "Fuzzing with available target source code", "Fuzzing with partially-available target source code", and "Fuzzing with no target source code" respectively. Further still fuzzing can be broken down into more specific sub-types such as "Coverage-Guided / Mutation Fuzzing" and "Generation Fuzzing".
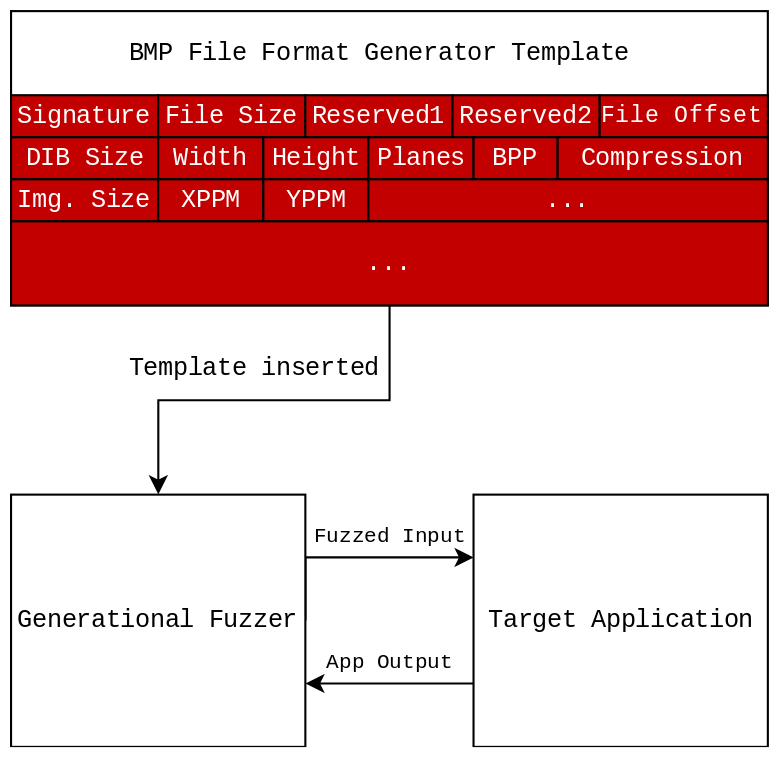
Generation Fuzzing
Generation Fuzzing is the act of using a "Generator" that is given to the fuzzer by the researcher. This "Generator" can, for instance, map out all possible fields of a .BMP file. The "Generator" can then mutate each of these fields separately to potentially cause crashes. By large, Generation fuzzing is considered more thorough for testing a particular type of target where the input can be described as a data set or data structure. This form of fuzzing is particularly useful in situation where specific fields can’t be modified or a certain structure needs to be maintained for the input to be valid. For example, if a JPEG reader is being fuzzed the input file should almost always start with FF and D8 or FF and D9 as these are the magic bytes to indiciate that the file is actually a JPEG. Leaving this to chance with other fuzzing techniques may result in a large number of files being rejected by the application as they don’t follow the correct format.
Mutation fuzzing
Mutation Fuzzing on the other hand gives much more leeway for input requirements as the only requirement that has to be met is that the input is valid for the target. This does not mean that the input has to contain evey possible field that the target accepts, only that it contains enough to be functional. For example, if there was a file format .X9 that had a large (64 byte) optional header and all inputs to a fuzzer did not contain this header then that header would never be targeted. This is because it was absent from the input data so the fuzzer has no ability to mutate something it is not aware of. This combined data set is generally referred to as a "Corpus" and it should be as thorough as possible for the target.
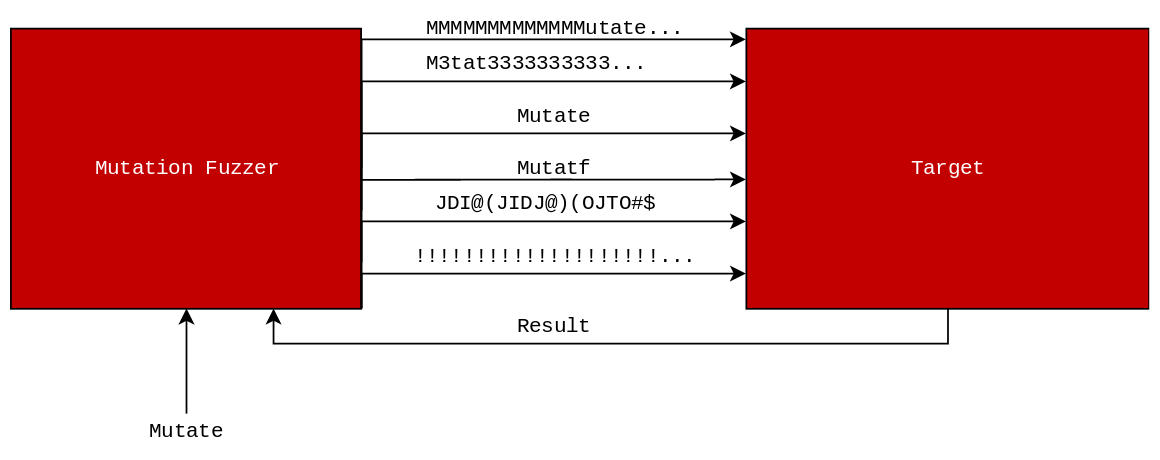
Coverage-Guided Fuzzing
Coverage-Guided Fuzzing is a form of "smart fuzzing" that involves instrumenting the target application beforehand. "Instrumentation" is the process of injecting code into a process at compile-time where execution paths can be determined by the fuzzer. The reason this is so useful is that when the fuzzer detects a new path can be reached by modifying an input it will attempt to reach that path by choice rather than by chance. This makes the method of Mutation Fuzzing a lot cleaner as it creates a positive feedback loop that will hit more of the application. The difficulty of using coverage-guided fuzzing is that it requires the source code to the application that is being targetted so that it may be compiled with the instrumentation. Some fuzzers will attempt to do instrumentation on already compiled software, but this can lead to significant performance hits.
Dumb Fuzzing
Inversely, Dumb Fuzzing involves feeding inputs (with or without structured mutation) to a target application without direct knowledge of the target's internals. This is also referred to as a black-box technique as the fuzzer is unaware of how exactly its inputs are affecting the target or what it could change to hit a different path.
Installing AFL
Installing AFL on Linux is fairly straight-forward, it can either be built directly from source via their github or pulling via a package repository such as Apt via sudo apt install afl.
Using AFL
Simple Example
On Linux there are a few things that need to be ran before AFL can work properly:
sudo /bin/sh -c "echo core > /proc/sys/kernel/core_pattern"
sudo /bin/sh -c "echo performance | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor"
AFL will complain and suggest to make these changes if you attempt to run it without them. Moving on, let's create a small test application to demonstrate AFL's fuzzing capabilities. The application will ask the user if they want to enter a password and then it will judge if the password was correct. However, we will not implement any checks based on input other than for correctness.
#include <stdio.h>
#include <string.h>
void process_password()
{
char enterpassword[2];
printf("Do you want to enter a password?:");
scanf("%s", enterpassword);
if(strcmp(enterpassword, "N") == 0)
return;
printf("You entered:");
printf(enterpassword);
printf("\n");
char password[256];
printf("Enter you password:");
scanf("%s", password);
if(strcmp(password, "S3cr3tP@ssw0rd!") == 0)
{
printf("Correct!\n");
}
else
{
printf("Incorrect.\n");
}
}
int main(int argc, char** argv)
{
process_password();
return 0;
}
AFL gives us two options to work with when it comes to inputs. We can either pass inputs in via standard-in (scanf, gets, cin, etc) or via arguments. The former is good for applications where either the target (or harness) is interacted with via a command line. The latter is useful when a file needs to be passed as the argument such as an image viewer wanting a path to open as part of the command line. Attempting to run AFL on the application without instrumentation will return an error message:
afl-fuzz 2.52b by
[+] You have 32 CPU cores and 1 runnable tasks (utilization: 3%).
[+] Try parallel jobs - see /usr/local/share/doc/afl/parallel_fuzzing.txt.
[*] Checking CPU core loadout...
[+] Found a free CPU core, binding to #0.
[*] Checking core_pattern...
[*] Checking CPU scaling governor...
[*] Setting up output directories...
[+] Output directory exists but deemed OK to reuse.
[*] Deleting old session data...
[+] Output dir cleanup successful.
[*] Scanning './Desktop/Inputs'...
[+] No auto-generated dictionary tokens to reuse.
[*] Creating hard links for all input files...
[*] Validating target binary...
[-] Looks like the target binary is not instrumented! The fuzzer depends on
compile-time instrumentation to isolate interesting test cases while
mutating the input data. For more information, and for tips on how to
instrument binaries, please see /usr/local/share/doc/afl/README.
When source code is not available, you may be able to leverage QEMU
mode support. Consult the README for tips on how to enable this.
(It is also possible to use afl-fuzz as a traditional, "dumb" fuzzer.
For that, you can use the -n option - but expect much worse results.)
[-] PROGRAM ABORT : No instrumentation detected
Location : check_binary(), afl-fuzz.c:6920
We can use the afl-gcc utility to compile our application with the necessary instrumentation for the fuzzer.
$ afl-gcc ./test.c
afl-cc 2.52b by
./test.c: In function ‘process_password’:
./test.c:14:9: warning: format not a string literal and no format arguments [-Wformat-security]
printf(enterpassword);
^~~~~~~~~~~~~
./test.c:8:2: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
scanf("%s", enterpassword);
^~~~~~~~~~~~~~~~~~~~~~~~~~
./test.c:19:2: warning: ignoring return value of ‘scanf’, declared with attribute warn_unused_result [-Wunused-result]
scanf("%s", password);
^~~~~~~~~~~~~~~~~~~~~
afl-as 2.52b by
[+] Instrumented 7 locations (64-bit, non-hardened mode, ratio 100%).
We've already got some pretty nasty warnings during compilation, but let's go ahead and let AFL run for a while with the given application. First, we need to make a folder for inputs and outputs. AFL requires a corpus of good inputs that it can work from before fuzzing begins.
mkdir ./Inputs
mkdir ./Outputs
echo "Y\ntest" > ./Inputs/input1
echo "N\n" > ./Inputs/input2
echo "Y\nS3cr3tP@ssw0rd\!" > ./Inputs/input3
echo "Y\n1235" > ./Inputs/input4
echo "Y\nblah" > ./Inputs/input5
echo "Y\nREEEEEE" > ./Inputs/input6
afl-fuzz -i ./Inputs -o ./Outputs ./a.out
After running for a while, this is the result we get:
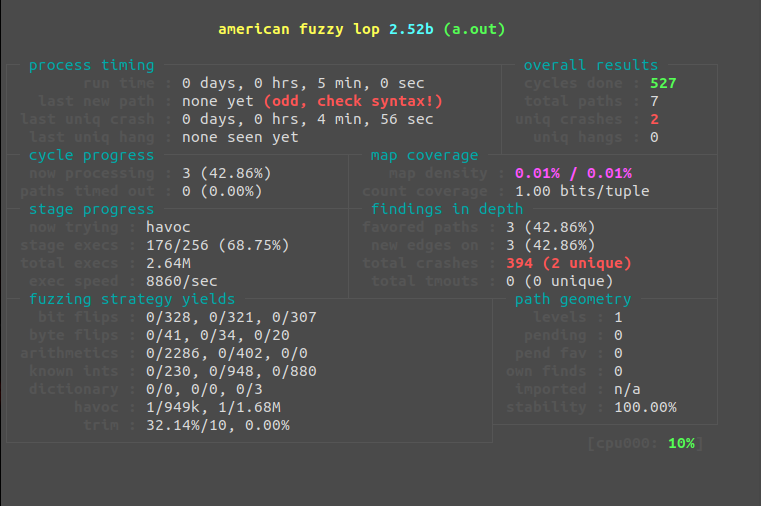
Even after only a few minutes, we've found 2 unique crashes and have crashed the application 483 times. The (odd, check syntax!) error message isn't relevant in this scenario as our execution paths are limited. If we were fuzzing a much larger application or library, this could be a cause for concern as it means we are repeating the same routines over and over. Although we have roughly 6000 executions per second, we can do much better if we use "persistent fuzzing."
Persistent Fuzzing
Persistent fuzzing is a feature of AFL that allows the target to be launched and restarted without fully terminating the application. This can be done by adding a while loop in a critical point of the code: while(AFL_LOOP(1000)) { Code }. Persistent fuzzing works best on code that is stateless and actually can introduce issues while fuzzing if performed on interactive targets or targets that have a state such as reading a buffered file. A very important detail is that our target can not be compiled using afl-gcc or afl-g++, it must be compiled using the LLVM binding with afl-clang-fast or afl-clang-fast++. Utilitizing this feature can introduce significant gains in execution speed as high as 8 times faster.
Below we give a brief example of a program that calls a stateless function. First, we'll compile it without the __AFL_LOOP logic and demonstrate the "before" execution speed. The following code sample is still compiled with afl-clang-fast ./persis.c even though the persistence isn't enabled. The inputs it is given are simple "aaa", "bbbbb" inputs.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void stateless_func(char* var)
{
char buffer[256];
memcpy(buffer, var, strlen(var));
printf(buffer);
}
int main()
{
char input[256];
read(0, input, 256);
stateless_func(input);
return 0;
}
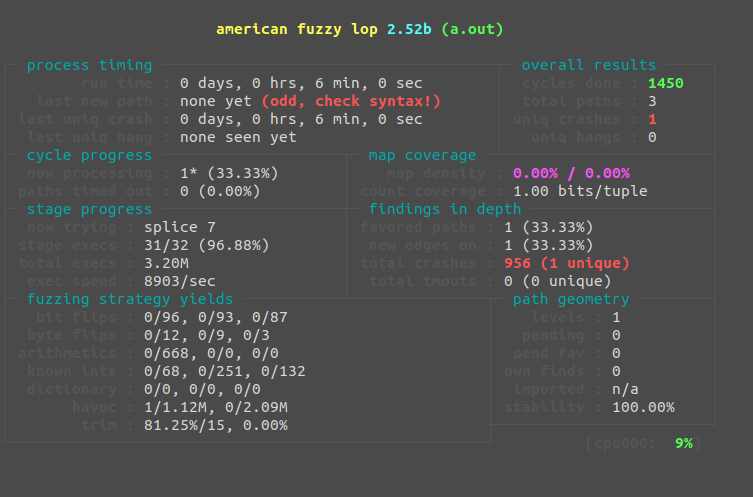
Running this code through AFL without persistent mode will introduce significant slowdown as the target has the be started, executed, and terminated every single time. This gives us around 9000 executions per second, but we can do much better. Let's add our persistence and see what kind of difference we can get.
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
void stateless_func(char* var)
{
char buffer[256];
memcpy(buffer, var, strlen(var));
printf(buffer);
}
int main()
{
char input[256];
while(__AFL_LOOP(1000))
{
read(0, input, 256);
stateless_func(input);
}
return 0;
}
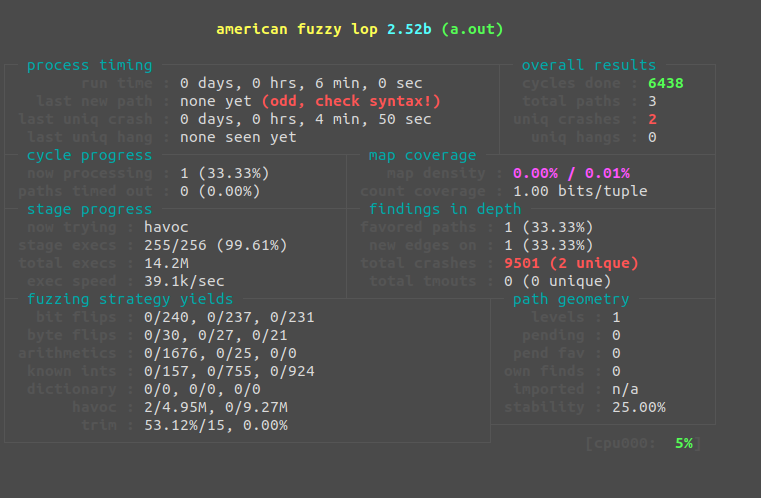
We now get around 40,000 executions per second, that's a 4.44x difference! Of course, this still isn't the best we can do. As all of our examples up to this point have been running in a single hardware thread with minimal utilization. AFL gives us a leg up with parallel fuzzing.
Parallel Fuzzing
CPUs have a number of hardware threads usually equal to double the amount of cores. This means that a dual core CPU will have 4 threads, a quad core CPU will have 8 threads, and an octa core CPU will have 16 threads. AFL give us the ability to create "Master" and "Slave" fuzzers. Master fuzzers will perform deterministic techniques while Slave fuzzers will only perform tweaks on existing data without further observation. While there isn't a true upper limit to the number of instances that can be spawned, it is advised to only run as many instances as you have threads available.
AFL's parallel fuzzing option is enabled by adding the -M (Master) or -S (Slave) flags to the launch parameters. The -o (Output) flag is now used to define a "sync" directory where all of the fuzzers will keep their backlogged test cases and their crashes will be saved. With all of these instances running, the afl-whatsup application can be used to determine the total execution speed across all instances and how many crashes have been found. Pointing the afl-whatsup application at the output "sync" directory will show the stats across all of the fuzzers.
Now let's give a demonstration of the previous sample (stateless_func) under the effects of parallel fuzzing. We will be using afl-launch to launch 32 instances of AFL against our target running in persistent mode. As we can't feasibly watch all 32 instances, we'll use the afl-whatsup utility on the output folder to gauge the effectiveness of our run.
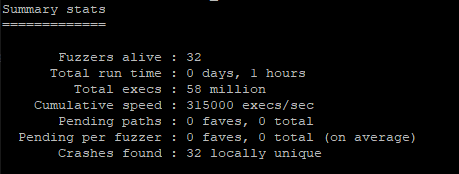
As you can see, we get a massive performance increase with the parallel fuzzing versus our original 39.1k executions per second. The 315k executions per second could trim days off a long-term fuzz analysis.
Wrapping up
Fuzzing can be an amazingly useful technique when searching for vulnerabilities in software. With a tool like AFL and a custom built harness, almost any application can be fuzzed. This leaves the scope of target selection mostly up to the researcher. There also exist other fuzzers that are more specialized such as the Facedancer board for USB fuzzing, or Nightmare for network protocol fuzzing. I hope this has been useful and I'll see you soon.